
ダブルアレイで高速でコンパクトな辞書を実装してみた!
IT技術

ダブルアレイを使って辞書を実装してみる
ダブルアレイは、トライ木を表現することができるデータ構造で、コンパクトで高速に辞書検索が行えるという特徴を持っています。
小さなサイズで、高速に辞書検索を行うことができるという特徴を持っています。
有名な形態素解析エンジンである「mecab」でも用いられています。
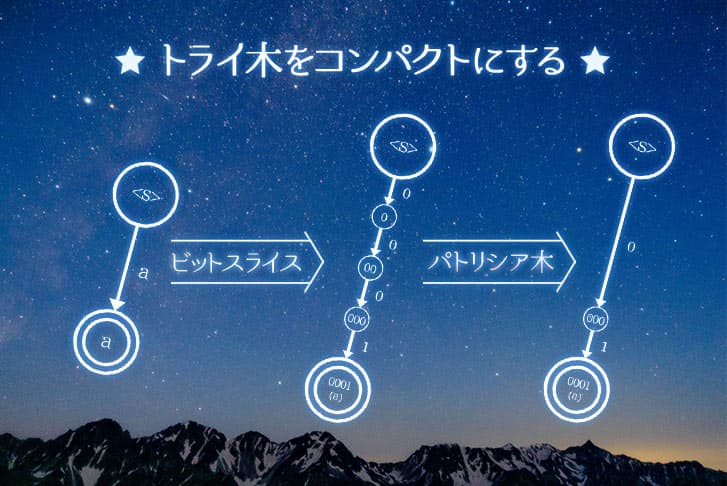
2本の配列を用いることでトライ木を表現

上の図のように、2本の配列を用いることでトライ木を表現します。
今回は、このダブルアレイについて解説をし、実際に辞書を実装、コードの解説も行っていきたいと思います!
ダブルアレイとトリプルアレイ
以前の記事では、トリプルアレイについて紹介をしました。
ダブルアレイは、このトリプルアレイを元に、配列を一本取り除くことで、検索速度は(ほぼ)そのままで、よりコンパクトにトライ木を格納することができます。
※ダブルアレイとトリプルアレイの関係について、詳しくはダブルアレイの元論文である『An Efficient Digital Search Algorithm by Using a Double-Array Structure(JI-Aoe.1989)』に書かれています
ダブルアレイも、トリプルアレイと元となるアイデアは同じなので、トリプルアレイが理解できていればダブルアレイの理解も簡単です。
今回は、トリプルアレイの仕組みが理解できているという前提で、ダブルアレイについて解説していきます。
トリプルアレイについて自信のない方は、以前の記事を参考にしてください。
 2020.01.15トリプルアレイで軽量で高速な辞書を作ってみた!軽量で高速に検索できる辞書システムをつくるトリプルアレイというデータ構造をご存知でしょうか?「ダブルアレイ」は聞いたこ...
2020.01.15トリプルアレイで軽量で高速な辞書を作ってみた!軽量で高速に検索できる辞書システムをつくるトリプルアレイというデータ構造をご存知でしょうか?「ダブルアレイ」は聞いたこ...
こちらの記事もオススメ!
トリプルアレイの復習
ダブルアレイの元となるトリプルアレイについて、少しだけ確認をしておきます。
トリプルアレイは、以下の図のように構築されるもので、3本の配列でトライ木を表現します。
3本の配列でトライ木を表現

3本の配列には「NEXT」「CHECK」「OFFSET」という名前がつけられており、それぞれ以下のような役割を担っています。
NEXT : 次に遷移するノードを格納する
CHECK : 正しい遷移であることを確認するために遷移元(親ノード)のidを格納する
OFFSET : 各ノードのずらし幅を格納する
このうち、「NEXT」と「CHECK」は同じ大きさとなります。
「OFFSET」だけ異なり、ノード数分の大きさとなります。
ダブルアレイ構築方法
それでは、ダブルアレイの構築方法について解説していきます。
今回は以前解説した、「トリプルアレイ」を利用して構築していきます。
トリプルアレイについては、以前の記事を参照してください。
トリプルアレイを2本の配列で表現するために、OFFSETを削除することを考えます。
そのためにまず、OFFSETが遷移の際にどんな役割をしているかを見てみましょう。
OFFSETの役割

この図から、OFFSETは「ノードのずらし幅を得るため」に使われていることがわかります。
このため、もしOFFSETを用いずにNEXTから直接ずらし幅が得ることができれば、OFFSETは不要となります。
「NEXTから直接ずらし幅を得る」というのは実はとても簡単で、NEXTにノードidではなくそのノードのずらし幅を直接格納しておけばよいのです。
このノードidの代わりにずらし幅を格納されたNEXTは、BASE配列とよばれます。

ここまでで、OFFSETを削除することができました。
CHECK配列について
しかし、これによりノードidの情報が失われてしまったので、ノードidによって正しい遷移であることを確認していたCHECK配列の方に問題がおきてしまいます。
これもさほど難しくなく、以下の図のようにCHECK配列にノードidの代わりにBASE配列上での遷移元のindexを保存しておけばよいです。
これは元のCHECK配列の要素を、NEXT配列のおなじ要素があるindexに置き換えることでできます。

ここまでで、ダブルアレイは完成です。
遷移が可能かの確認
実際に、遷移が可能かどうかを確認しましよう。
単語idが「0」である「a」と単語idが「2」である「c"」いう単語が順に入力された場合の遷移を考えます。
最初は、ルートノードにいます。
(1) ルートノードのずらし幅は0ですので、index = 0+(aの単語id) = 0+0 = 0
(2) CHECK[0]をみると、CHECK[0] = -1です。
-1はルートノードを表すことにしているので、正しく遷移できています。
(3) BASE[0]をみます。
BASE[0] = -1 ですので、次のずらし幅は-1ということがわかります。

ここまでで、「a」の入力の処理が終わり、現時点でindexは「0」となります。
「c」の入力の処理
続いて、「c」の入力の処理に移ります。
(4) index = -1 + (cの単語id) = -1 + 2 = 1
CHECK[1]をみると、CHECK[1] = 0です。
(5) 前のindexは0だったので、正しく遷移できています。
cの次は入力が無いのでindex = 1の位置で終了です。

以上でBASEとCHECK配列で、ダブルアレイの構築は完了です。
ダブルアレイの実装(準備)
それでは、実際に、ダブルアレイを実装し、辞書システムを作っていきましょう!
言語は、Pythonを用います。
ダブルアレイの実装にはいくつか方法がありますが、今回は「トリプルアレイが構築された状態から、ダブルアレイに変換する」という方法で実装します。
要件
要件は以下です。
トリプルアレイのときと同様です。
- 単語とその読み方のペアを登録する
- 単語を入力することで読み方を出力する
- 単語に使える文字はasciiのみ
単語とその読み方のペアとして、今回も前回同様以下のデータを用います。
| 単語 | 読み方 |
| a | エー |
| ab | エービー |
| ac | エーシー |
| abc | エービーシー |
| bc | ビーシー |
まずは、準備段階として、構造体から作っていきます。
今回は、DoubleArray というクラスを作成します。
なお、ダブルアレイでは以前の記事で作成した、TripleArrayクラスを用いています。
DoubleArrayクラスは、BASE、CHECK、itemsという3つの変数を持ちます。
BASEは、トリプルアレイのオフセットと同じ長さとなるので、TripleArrayのOFFSETSと同じ長さで初期化します。
CHECK、itemsは、トリプルアレイのCHECKと同じ長さで初期化します。
__init__() 関数の最後の行で、後に説明するmake_double_array() を呼び出し、トリプルアレイを元にダブルアレイを構築します。
1class DoubleArray:
2 """
3 ダブルアレイクラス
4
5 Attributes
6 ----------
7 BASE : list
8 ずらす幅を格納するBASE配列
9
10 CHECK : list
11 遷移元を格納するCHECK配列
12
13 items : list
14 登録された単語の読み方
15 単語終端ノード以外の場合はNone
16
17 """
18
19 def __init__(self, triple):
20 """
21
22 Parameters
23 ----------
24 triple : triple
25 ダブルアレイの元となるトリプルアレイ
26 """
27 # BASEにはずらし幅が入る(ずらし幅は-(VOCAB_SIZE)以下になることはない
28 # 少し余裕をもたせて-(VOCAB_SIZE+10)で初期化する
29 self.BASE = [-(tr.VOCAB_SIZE+10)] * len(triple.OFFSETS)
30 self.CHECK = [None] * len(triple.CHECK)
31 self.items = [None] * len(triple.CHECK)
32
33 self.make_double_array(triple)ダブルアレイ実装(構築部分)
TripleArrayクラス から、ダブルアレイを構築するmake_double_array() を実装していきます。
このメソッドは、TripleArray の NEXT、CHECK配列を書き換えることでダブルアレイを構築していきます。
トリプルアレイで、ずらす処理などは終わっているので、以下の2つの処理をすれば完了です。
1. NEXT をノードidではなく、ずらし幅に変更して BASE を作成
2. CHECK をノードidでなく、index に変更
コード
1class DoubleArray:
2
3 .
4 .
5 .
6
7 def make_double_array(self, triple):
8 """
9 トリプルアレイクラスからダブルアレイを構築する
10
11 Parameters
12 ----------
13 triple : triple
14 ダブルアレイの元となるトリプルアレイ
15 """
16
17 node_to_index = [-(tr.VOCAB_SIZE+10)] * len(triple.CHECK)
18 # NEXTを1要素ずつループし、BASEとitemsを作成
19 # ついでにCHECK作成の準備をする
20 for i in range(len(triple.NEXT)):
21 N = triple.NEXT[i]
22 if N == -1:
23 # -1の場合は要素が無いということなのでスルー
24 continue
25 self.BASE[i] = triple.OFFSETS[N] # BASEにずらし幅を代入
26 self.items[i] = triple.items[N] # itemsをノードidでなくindexから得られるように位置を変更
27
28 node_to_index[N] = i # 後でcheck配列を作りやすいようにノードidからindexを得られるようにメモしておく
29
30 # CHECKを1要素ずつループし、新しいCHECKを作成する
31 for i in range(len(triple.CHECK)):
32 if triple.CHECK[i] == 0:
33 # triple.CHECK[i]が0のときはルートノードを表すので新しいCHECKでは-1とする
34 self.CHECK[i] = -1
35 else:
36 self.CHECK[i] = node_to_index[triple.CHECK[i]]解説
1ループ目で TripleArray の OFFSETS から BASE を作成、また items も作成します。
さらに、後に CHECK を作成する際に、ノードid からそのノードを表す NEXT の index を得やすいようにnode_to_index という配列を作成しておきます。
2ループ目では、node_to_index から新しい CHECK配列 を作成しています。
ダブルアレイ実装(検索部分)
続いて、検索を行うquery()を実装していきます。
こちらは、検索文字列を一文字ずつループすることで、ダブルアレイを遷移していきます。
最後の index にたどり着いたら、items に格納されている、その index に対応する要素を返します。
コード
1class TripleArray:
2
3 .
4 .
5 .
6
7 def query(self, word):
8 """
9 検索する
10
11 Parameters
12 ----------
13 word : str
14 検索したい単語
15
16 Returns
17 -------
18 item :str or None
19 検索結果
20 見つからなかった場合はNone
21 """
22
23 def get_char_num(c):
24 """
25 文字のidを返す
26 aが0, bが1, ..., zが25となる
27 """
28 return ord(c) - ord('a')
29
30 # ルートノードにいる状況で初期化
31 offset = 0
32 pre_index = -1
33
34 for c in word:
35 char_num = get_char_num(c)
36
37 tmp_index = offset + char_num # indexを計算
38
39 if not(0 <= tmp_index < len(self.CHECK)):
40 # tmp_indexがCHECKのインデックスの範囲に無いっていない場合は遷移できないのでNone
41 return None
42 if self.CHECK[tmp_index] != pre_index:
43 # 正しい遷移でない場合はそのwordは書くのぬされていないのでNoneを返す
44 return None
45
46 offset = self.BASE[tmp_index] # 次のノードのずらし幅をget
47 pre_index = tmp_index
48
49 return self.items[tmp_index]ダブルアレイの実装(全体)
ここまでで、ダブルアレイを用いた辞書の実装が完了です。
すべてのコードをまとめたものが以下になります。
全体のコード
1import sys
2import trie as tr
3import triple_array as triple
4
5
6class DoubleArray:
7 """
8 ダブルアレイクラス
9
10 Attributes
11 ----------
12 BASE : list
13 ずらす幅を格納するBASE配列
14
15 CHECK : list
16 遷移元を格納するCHECK配列
17
18 items : list
19 登録された単語の読み方
20 単語終端ノード以外の場合はNone
21
22 """
23
24 def __init__(self, triple):
25 """
26
27 Parameters
28 ----------
29 triple : triple
30 ダブルアレイの元となるトリプルアレイ
31 """
32 # BASEにはずらし幅が入る(ずらし幅は-(VOCAB_SIZE)以下になることはない
33 # 少し余裕をもたせて-(VOCAB_SIZE+10)で初期化する
34 self.BASE = [-(tr.VOCAB_SIZE+10)] * len(triple.OFFSETS)
35 self.CHECK = [None] * len(triple.CHECK)
36 self.items = [None] * len(triple.CHECK)
37
38 self.make_double_array(triple)
39
40 def make_double_array(self, triple):
41 """
42 トリプルアレイクラスからダブルアレイを構築する
43
44 Parameters
45 ----------
46 triple : triple
47 ダブルアレイの元となるトリプルアレイ
48 """
49
50 node_to_index = [-(tr.VOCAB_SIZE+10)] * len(triple.CHECK)
51 # NEXTを1要素ずつループし、BASEとitemsを作成
52 # ついでにCHECK作成の準備をする
53 for i in range(len(triple.NEXT)):
54 N = triple.NEXT[i]
55 if N == -1:
56 # -1の場合は要素が無いということなのでスルー
57 continue
58 self.BASE[i] = triple.OFFSETS[N] # BASEにずらし幅を代入
59 self.items[i] = triple.items[N] # itemsをノードidでなくindexから得られるように位置を変更
60
61 node_to_index[N] = i # 後でcheck配列を作りやすいようにノードidからindexを得られるようにメモしておく
62
63 # CHECKを1要素ずつループし、新しいCHECKを作成する
64 for i in range(len(triple.CHECK)):
65 if triple.CHECK[i] == 0:
66 # triple.CHECK[i]が0のときはルートノードを表すので新しいCHECKでは-1とする
67 self.CHECK[i] = -1
68 else:
69 self.CHECK[i] = node_to_index[triple.CHECK[i]]
70
71
72 def query(self, word):
73 """
74 検索する
75
76 Parameters
77 ----------
78 word : str
79 検索したい単語
80
81 Returns
82 -------
83 item :str or None
84 検索結果
85 見つからなかった場合はNone
86 """
87
88 def get_char_num(c):
89 """
90 文字のidを返す
91 aが0, bが1, ..., zが25となる
92 """
93 return ord(c) - ord('a')
94
95 # ルートノードにいる状況で初期化
96 offset = 0
97 pre_index = -1
98
99 for c in word:
100 char_num = get_char_num(c)
101
102 tmp_index = offset + char_num # indexを計算
103
104 if not(0 <= tmp_index < len(self.CHECK)):
105 # tmp_indexがCHECKのインデックスの範囲に無いっていない場合は遷移できないのでNone
106 return None
107 if self.CHECK[tmp_index] != pre_index:
108 # 正しい遷移でない場合はそのwordは書くのぬされていないのでNoneを返す
109 return None
110
111 offset = self.BASE[tmp_index] # 次のノードのずらし幅をget
112 pre_index = tmp_index
113
114 return self.items[tmp_index]構築、検索の実験
最後に、ダブルアレイの構築、検索の実験を行います。
1trie = tr.Trie()
2
3trie.insert("a", "エー")
4trie.insert("aa", "エーエー")
5trie.insert("ab", "エービー")
6trie.insert("abc", "エービーシー")
7trie.insert("b", "ビー")
8trie.insert("bc", "ビーシー")
9#trie.insert("c", "シー")
10
11## ここまででtrie木を作成
12
13triple_array = triple.TripleArray(trie)
14
15## ここまででトリプルアレイを構築
16
17
18double_array = DoubleArray(triple_array)
19
20print(double_array.query("a"))
21print(double_array.query("abc"))
22print(double_array.query("bc"))
23print(double_array.query("abcd"))結果
これを実行すると、以下のような結果になります。
1エー
2エービーシー
3ビーシー
4None辞書に insert した単語はきちんと読み方が「表示」され、そうでない単語は「None」となっていることがわかります。
さいごに
お疲れさまでした!
ダブルアレイを理解するのはかなり難しいかもしれませんが、非常に実用的なデータ構造です。
トリプルアレイから理解していけば、ダブルアレイも必ず理解できるようになるはずです。
ぜひチャレンジしてみてくださいね!
こちらの記事もオススメ!
関連記事
 2019.08.08トライ木で高速な辞書を作ってみた!トライ木で高速な辞書を作りたい!トライ木(英: trie)というデータ構造を知ってますか?トライ木はテキストを扱う際に...
2019.08.08トライ木で高速な辞書を作ってみた!トライ木で高速な辞書を作りたい!トライ木(英: trie)というデータ構造を知ってますか?トライ木はテキストを扱う際に...
2020.01.15トリプルアレイで軽量で高速な辞書を作ってみた!軽量で高速に検索できる辞書システムをつくるトリプルアレイというデータ構造をご存知でしょうか?「ダブルアレイ」は聞いたこ...
2020.01.28ダブルアレイで高速でコンパクトな辞書を実装してみた!ダブルアレイを使って辞書を実装してみるダブルアレイは、トライ木を表現することができるデータ構造で、コンパクトで高速に辞...


ライトコードでは、エンジニアを積極採用中!
ライトコードでは、エンジニアを積極採用しています!カジュアル面談等もございますので、くわしくは採用情報をご確認ください。
採用情報へ
「好きを仕事にするエンジニア集団」の(株)ライトコードです! ライトコードは、福岡、東京、大阪、名古屋の4拠点で事業展開するIT企業です。 現在は、国内を代表する大手IT企業を取引先にもち、ITシステムの受託事業が中心。 いずれも直取引で、月間PV数1億を超えるWebサービスのシステム開発・運営、インフラの構築・運用に携わっています。 システム開発依頼・お見積もり大歓迎! また、現在「WEBエンジニア」「モバイルエンジニア」「営業」「WEBデザイナー」を積極採用中です! インターンや新卒採用も行っております。 以下よりご応募をお待ちしております! https://rightcode.co.jp/recruit








